-
Elasticsearch Shard & 성능DEV 2023. 12. 2. 10:57

load Elasticsearch 샤드의 개수에 따른 색인(index)과 검색(search) 성능에 관한 이야기.
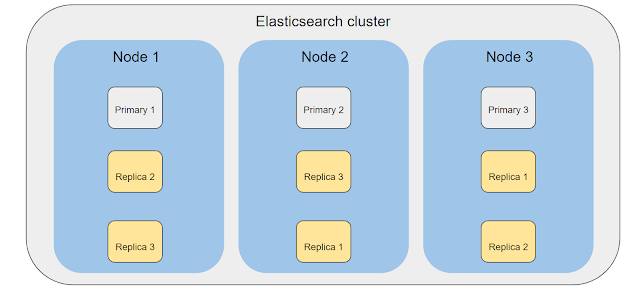
elasticsearch cluster, node, index Cluster
- 하나 이상의 노드로 구성
Node
- 단일 ES인스턴스
- master node, data node
- 서버별 1개 노드 설정을 추천
Index
- 문서 모음
shard → lucene index
- 검색/색인이 병렬로 동작할 수 있도록 데이터를 여러 개의 작은 조각으로 나누는 것.
- primary shard, replica shard
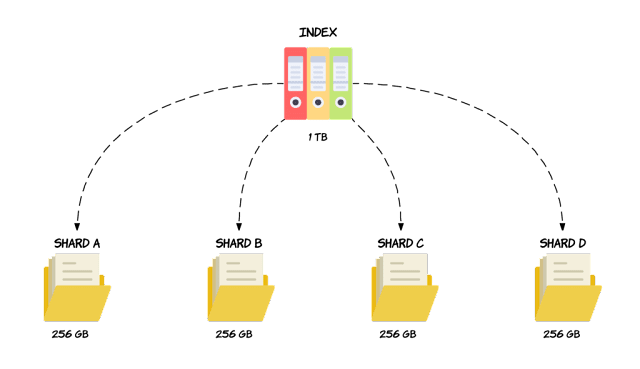
shard = lucene index Primary shard
- index(색인), search(검색)
- 기본적으로 색인 성능을 위함
- 인덱스 생성 후, 데이터 생성전에만 shard size 설정 가능
- 7.x default 1개, 6.x default 5개
Replica shard
- search
- 검색 성능을 위함, 언제든지 추가,제거 가능
- production 클러스터에는 2개이상 유지하는 것을 추천
- higher throughput, stronger failover.
- 많이 설정할 수록 스토리지 많이 사용
- default 1개
Shard count

1 primary shard, 1 replica shared - index1이 3개의 primary shard(Ap, Bp, Cp)와 1개의 replica shard(Ar, Br, Cr)를 가지고 있다.
- index 1 → primary shard 3(Ap, Bp, Cp), replica shard 1(Ar, Br, Cr)

3 primary shard, 2 replica shard - index는 3개의 primary shard(Ap, Bp, Cp)와 2개의 replica shard(Ar-0, Br-0, Cr-0, Ar-1, Br-1, Cr-1)를 가지고 있다.
- index → primary shard 3(Ap, Bp, Cp), replica shard 2 (Ar-0, Br-0, Cr-0, Ar-1, Br-1, Cr-1)
Shard design
- number of shards(3, 6, 9) >= number of data nodes (3)
- number of replica(0, 1, 2) <= number of data nodes - 1 (3 - 1)
Multiple shard for indexing
primary shard는 기본적으로 index 작업을 병렬화 하는 데 사용
5 primary shards, 100 docs → bulk index → each shard 20 docs parallel indexing
shard가 많을 수록 인덱싱이 빠름.
노드 수의 배수로 primary shard를 설정
Multiple shard for searching
각 샤드는 인덱스의 부분만 포함, 검색 요청하면 coordinating node에 의해
→ 인덱스에 포함된 샤드를 look up
→ coordinating node가 쿼리를 모든 샤드에 전달
→ 각 샤드는 문서id/score 결과 목록을 로컬에서 계산
→ 각 노드별 결과를 coordinating node 전송 → 병합 → 각 샤드에서 실제 문서 가져오기
search 쿼리 병렬처리 하지만 → 너무 많은 shard설정 시 → 오버헤드 발생
→ 메모리, CPU 리소스 점유

multiple shard for searching - 검색량이 감당할수 없을 만큼 많아진다면, node.data, node.master 모두 false로 설정한 노드를 추가하는 것도 방법 (coordinating 역할만을 하는 node)
- 추가한 노드들은 요청을 받고 데이터 노드로 요청을 분배하는 작업을 수행(coordinating node)
- 샤드를 실제 검색하는 노드들은 클라이언트와 커낵션을 관리하지 않아도 됨.
Trade off
빠른 인덱싱을 위해서는 많은 primary shard, 적은 replica shard가 좋고,
빠른 검색을 위해서는 적은 수(너무 많지 않은)의 primary shard가 좋다.
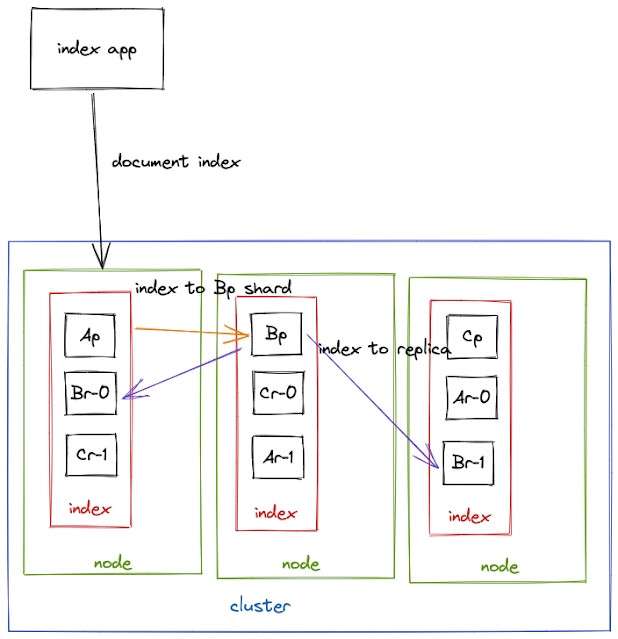
multiple shard for indexing - primary shard, 모든 replica shard에 색인이 되어야 요청이 완료
- 빠른 색인이 필요하다면 임시적으로 replica shard 숫자를 줄이고 종료된 후 추가 하기도 함
Generic guideline
for logging → shard sizes between 10~50GB
for search → 20-25GB
Reference
https://www.elastic.co/guide/en/elasticsearch/reference/current/size-your-shards.html
https://www.arcanna.ai/post/elasticsearch-shard-optimization
https://docs.rackspace.com/blog/clustered-elasticsearch-indexing-shard-and-replica-best-practices/
https://qbox.io/blog/optimizing-elasticsearch-how-many-shards-per-index
https://opster.com/guides/elasticsearch/capacity-planning/elasticsearch-number-of-shards/
728x90'DEV' 카테고리의 다른 글
K8S, DNS 간헐적 5~15초 지연 (2) 2023.12.02 Test Double (1) 2023.12.02 Dependency Mechanism (2) 2023.12.02 slf4j, facade, TDD (1) 2023.12.02 2022 카카오 공채 코딩테스트 감독을 하면서.. 그리고 TDD (2) 2023.12.02