-
advanced RAGDEV 2024. 11. 9. 10:46

RAG overview

RAG overview Naive RAG
https://developer-as-job.tistory.com/48
simple RAG pipeline
RAGRetrieval augmented generation (RAG: 검색 증강 생성)할루시네이션, 학습되지 않은 최신 데이터, 메모리 이슈해결RAG의 간단한 인덱싱 파이프라인 4단계원본 데이터에서 데이터 로딩(load data)큰 문서를
developer-as-job.tistory.com
Naive RAG와 단점
- 검색 - 검색자가 모든 정보를 가져오지 못하거나 잘못된 정보를 가져오는 경우 정확도와 재현율이 낮음
- 증강 - 정보가 여러 청크에서 출처 된 경우, 정보가 분리되어 의미를 잃고 LLM을 혼란스럽게 할 수 있음. 또한 검색된 정보에서 중복 및 반복의 가능성이 매우 높음
- 생성 - 최적이 아닌 검색 및 증강의 결과로 LLM은 정보로 인해 압도당하고 혼란스러워질 수 있음. 또한 LLM이 검색된 정보에 지나치게 의존하고 고유한 매개변수 지식을 사용하는 것을 잊는 것으로 관찰됨.
RAG Failuer points

RAG Failuer points https://arxiv.org/pdf/2401.05856.pdf
Query Process시 실패 요소와 해결 방안
Incorrect Specificity (잘못된 구체성)
- Advanced retrieval strategies
Missed Top Ranked (상위 문서 누락)
- Hyperparameter tuning & RerankingNot in Context (맥락 맞지 않음)
- Tweak retrieval strategies & Finetune embeddingsWrong Format (잘못된 포맷)
- Better prompting, output parsing, pydantic programs, OpenAI JSON modeIncomplete (불완전)
- Query transformationsNot Extracted (추출되지 않음)
- Clean your data, prompt compression, LongContextReorderOrchestration layer에서 할 수 있는 일들
위에서 언급한 이슈를 해결하기 위한 구체화 방안, (오케스트레이션 레이어에 한함)
HyDE
LLM에 쿼리에 대한 가상 응답을 생성하도록 요청 → 쿼리 벡터와 함께 해당 벡터를 사용하여 검색 품질을 향상
https://boston.lti.cs.cmu.edu/luyug/HyDE/HyDE.pdf
Context enrichment
더 나은 검색 품질을 위해 더 작은 덩어리를 검색하지만, LLM이 추론할 주면 콘텍스트를 추가하는 것
검색된 작은 청크 주변의 문장으로 컨텍스트를 확장
문서를 더 작은 하위 청크를 포함하는 여러 개의 큰 상위 청크로 반복적으로 분할Sentence Window Retrieval

Sentence Window Retrieval 녹색 부분은 인덱스 검색 중 발견된 문장 임베딩, 검정+녹색 문단 전체를 LLM에게 제공
https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/MetadataReplacementDemo.html
Parent-child chunks Retrieval
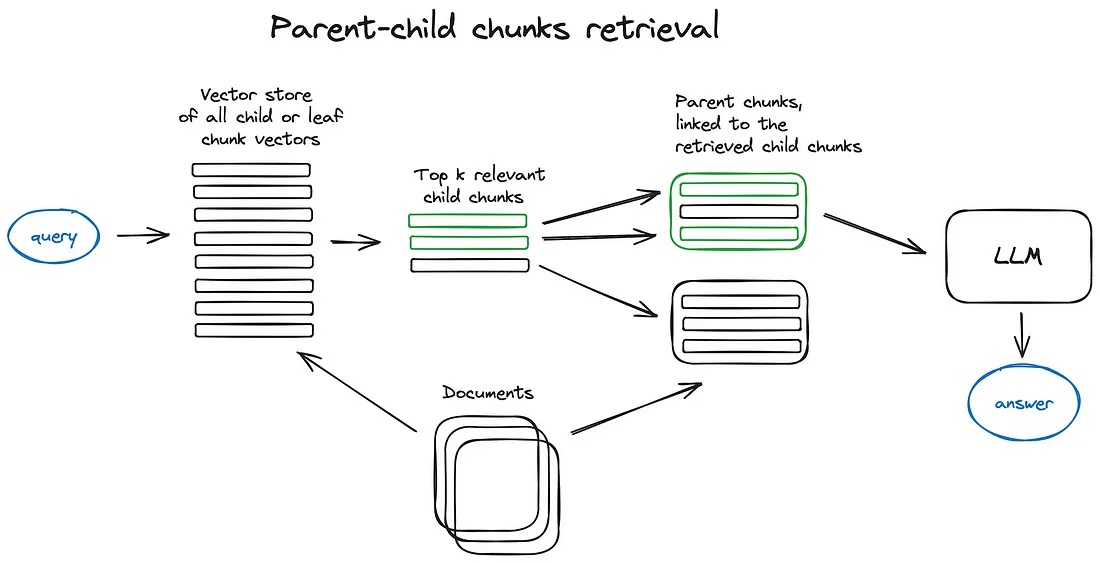
Parent-child chunks Retrieval sentence window retriever와 유사
작은 청크를 가져온 다음 검색된 상위 k개 청크 중 n개 이상의 청크가 동일한 상위 노드에 연결된 경우 상위 노드를 LLM에게 제공
https://python.langchain.com/docs/how_to/parent_document_retriever/
Hybrid search

Hybrid search 키워드 기반 검색(BM25), 벡터검색 등 두 가지 검새결과를 동시에 사용
쿼리와 저장된 문서 간 의미적 유사성(vectorDB), 키워드 일치를 모두 고려하여 두 개의 보완적인 검색알고리즘이 결합→ 더 나은 검색 결과 제공
순위 재지정(rerank) 필요
https://python.langchain.com/docs/how_to/ensemble_retriever/Query transformations
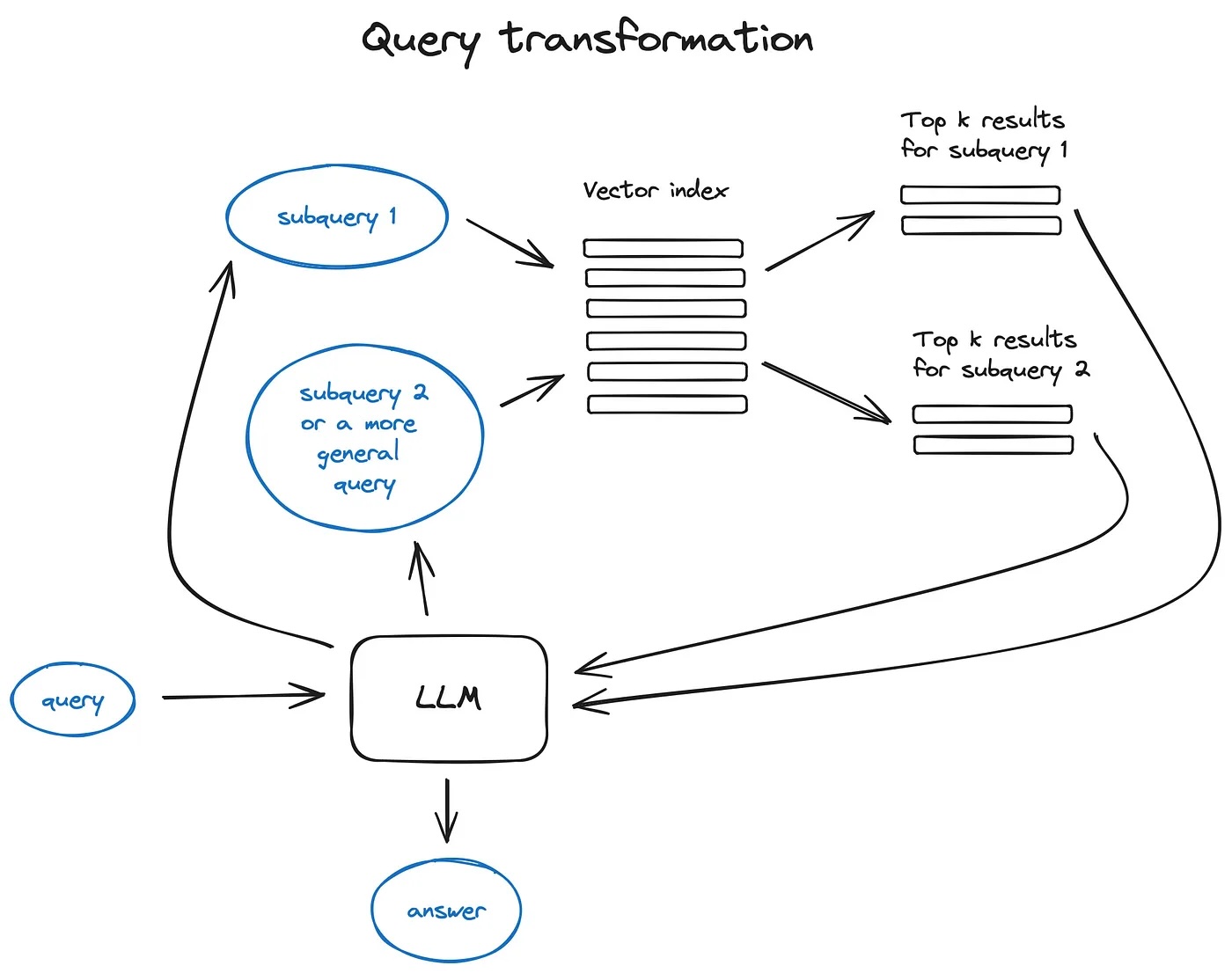
Query transformations 쿼리가 복잡한 경우 LLM을 이용해 쿼리를 여러 하위 쿼리로 분해
subQuery
- step-back prompting- https://arxiv.org/pdf/2310.06117.pdf
Advanced RAG

Advanced RAG Advanced RAG는 Native RAG의 부족함을 개선하기 위해 개발된 패러다임
주로 검색 및 생성의 질을 향상하기 위한 사전 및 사후 검색 방법을 포함- Pre-Retrieval Process
- Post-Retrieval Process
- RAG Pipeline Optimization
pre-retriever-process
HyDE
Query transformations
- subQuery (step-back)
- query reform (query re-writing)RAG pipeline Optimization
Hybrid retriever
- BM25, vector
Recursive retriever
- sentence window retrieverpost-retriever-process
rerank
prompt compressionagentic RAG
모델이 스스로 query transformation, query routing을 판단하고 실행하도록 agent개념이 들어간 advanced RAG

advanced RAG with agents 여러 agent가 협력하여 답을 찾아가는 multi-document agents

multi-document agents Ref.
https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6
728x90'DEV' 카테고리의 다른 글
RAG 개선, 평가 방법 (1) 2024.11.11 vectorDB 없이 검색api만으로 RAG app만들기 (3) 2024.11.10 simple RAG pipeline (3) 2024.11.08 LLM 기반 챗봇 설계, 구조 변화 (1) 2024.11.07 블록체인과 해쉬 (0) 2024.07.21